
In this series we have discussed how the HPE SimpliVity platform intelligently places vm’s along with their associated data containers and how these data containers are automatically provisioned and distributed across a cluster of nodes.
- Part 1 covers how data of a virtual machine is stored and managed within an HPE SimpliVity Cluster
- Part 2 explains how the HPE SimpliVity Intelligent Workload Optimizer (IWO) works, and how it automatically manages VM data in different scenarios
- Part 3 outlines options available for provisioning VMs
- Part 4 covers how the HPE SimpliVity platform automatically manages virtual machines and their associated Data Containers after initial provisioning, as virtual machines grow (or shrink) in size
Intelligent Workload Optimizer and Auto Balancer are not magic wands; they work together to balance existing resources, but cannot create resources in an overloaded DC and in some scenarios manual balancing may be required.
This post explores some of these scenarios, how to analyze resource utilization and manually balance resources within a cluster if required.
Analyzing resource utilization – capacity alarms
Total physical cluster capacity is calculated and displayed as the total aggregate available physical capacity from all nodes within a cluster. As previously stated, we do not report on individual node capacity within the vCenter plugin.

While overall cluster aggregate capacity may be low, it is possible that an individual node(s) may become space constrained. In this case an alarm in vCenter server will be triggered for the node in question.
- If the Percentage of occupied capacity is more than 80 and less than 90 percent then the Capacity Alarm service will alarm “WARN” event
- If the percentage of occupied capacity is more than 90 Percent then the capacity alarm service will alarm “ERR” event.
The below screen shot illustrates a node generating an 80% space utilization warning.
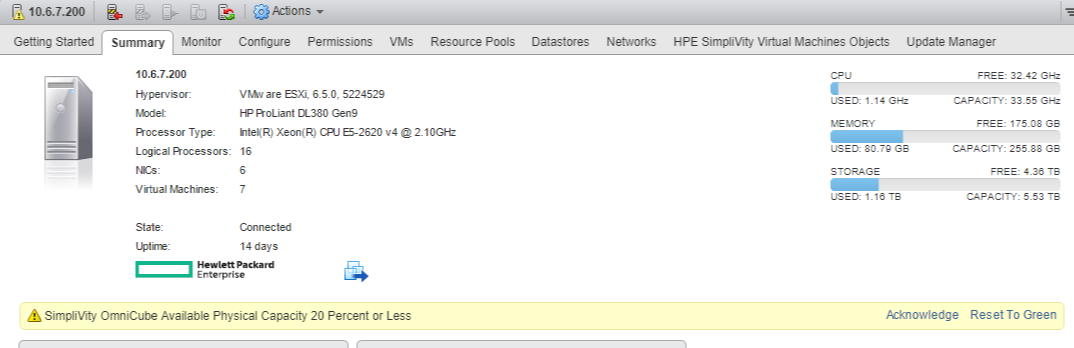
How can overall clusters aggregate capacity remain low within a cluster while an individual node(s) may become space constrained ? lets look a the table below.
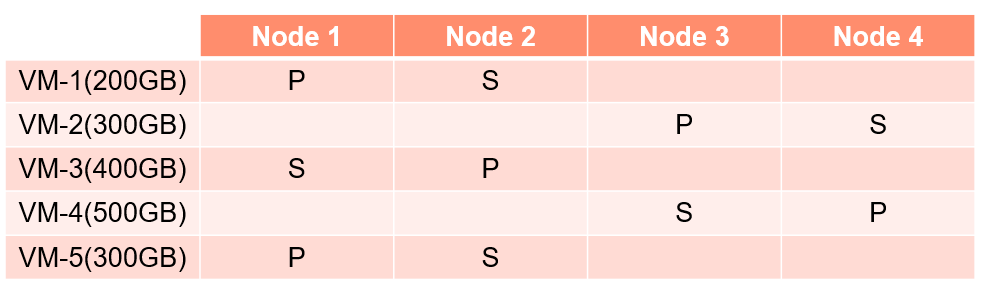
In the simplistic example (however the real world analogy is similar) lets assume physical node capacity of 2TB for each node, on disk vm space after de-duplication and compression is listed. Therefore we know the following.
- Total cluster capacity is 8TB
- Currently, cluster space consumption 3.4TB
- IWO / balancing service has distributed load evenly.
- Total cluster consumption is 42.5% (I’ll spare you the math!)
- If any one node exceeds 1.6TB utilization in this scenario an 80% capacity alarm will be triggered for that node..
If we were to add more virtual machines to this scenario or grow existing virtual machine sizes we can trigger 80% and 90% utilization alarms for two nodes within this cluster (as consumed on-disk space will scale lineally for both nodes that contain the associated primary and secondary data containers) however in the real world things can be slightly more nuanced for a number of reasons.
- Odd number clusters. Odd number clusters may not scale lineally in every scenario. One node in the cluster will be forced to house more primary and secondary copies of virtual machine data. This may trigger a capacity alarm.
- VM’s will have backups of various sizes associated with them (stored on the same nodes as the primary and secondary data contains for de-duplication efficiency) along with backups of vm’s from other clusters (remote backups), as remote and local backups grow / shrink in size and eventually timeout different nodes can experience different utilization levels.
- VM’s with highly unique data which does no de-duplicate very well.
Analyzing resource utilization – node & vm utilization
Use the dsv-balance-show with the –-showHiveName –consumption –showNodeIp arguments to view individual node capacity and virtual machine consumption. This command can be issued from any node within the cluster.
Note: You need to elevate to the root user to use this command.
- sudo su
- source /var/tmp/build/bin/appsetup
- dsv-balance-show –showHiveName –consumption –showNodeIp
To obtain the full list of command options issue the –help switch
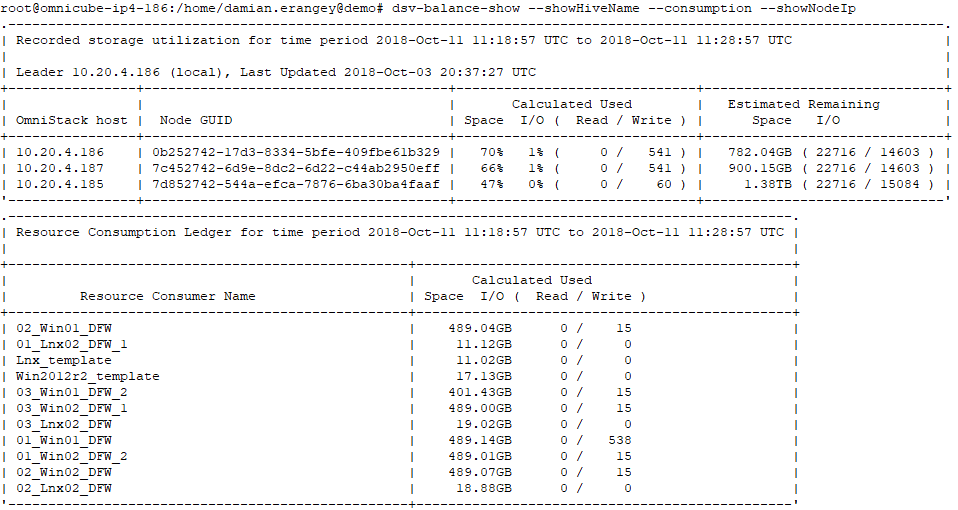
The above output from dsv-balance-show tell us the following
- Used and remaining space per node
- On-disk consumed space of each VM
- Consumed I/O of each node and VM (Note this is only a point in time snapshot of the node/vm’s when the command was issued)
Analyzing resource utilization – viewing vm data container placement
The dsv-balance-manual command is a powerful tool and be used to accomplish several tasks.
- Gather current guest virtual machine data including data container node residence, ownership, and IOPS statistics.
- Gather backup information for each VM (number of backups).
- Provide the ability to manually migrate data containers and(or) backups from one node to another.
- Provide the ability to evacuate all data from a node to other nodes within the cluster automatically.
- Re-align backups that may have become scattered.
dsv-balance-manual displays the output to the screen you will have to scroll backup on your ssh session !) and creates an analogous .csv ‘distribution’ file named: /tmp/replica_distribution_file.csv.
If invoked with the –csvfile argument, the script executes the commands to effect any changes made to the .csv file (more on that later).
Lets explore each functionality.
Listing data container node locations, ownership, on-disk consumed size and current IOPS statistics
Issuing the command dsv-balance-manual without any arguments is shown below, after the command is issued you will be prompted to select the required Datacenter/Cluster you wish to query. The following information is outputted directly to the console.
- VM ID (Used for CSV file tracking)
- Owner (which node is currently running the vm)
- Node columns (weather the node listed contains a primary or seconday data constainer for the vm)
- IO-R (vm read IOPS)
- IO-W (vm write IOPS)
- SZ(G) (on disk consumed sixe of the vm)
- Name (vm name)
- IOPS R (aggregate node read IOPS)
- IOPS W (aggregate node write IOPS)
- Size G (total consumed node on-disk space)
- AVAIL G (total remaining node on-disk space)
Note: Consumed on-disk space is a combination of virtual machine, local and remote backup consumption. However only on-disk vm-size is broken out in the SZ(G) column

The following blog post is an excellent way to gather the same information using powerCli
Listing additional backup information for each vm (number of backups)
Issuing the command dsv-balance-manual -q will add additional backup information. Note only local backups are listed. Remote backups (backups of vm’s stored from other clusters) are not listed.
Backup count per vm is listed, if the native column is 100% this indicates that all backups are stored along with the parent vm (ensuring maximum de-duplication efficiency).
Backups can become scattered if the node running the parent vm is offline for an extended period of time (the HPE SimpliVity DVP will choose an alternative node to house the backups) however the auto balancer service should automatically re-align the backups.
Note: dsv-balance-manual does not list local or remote backup sizes
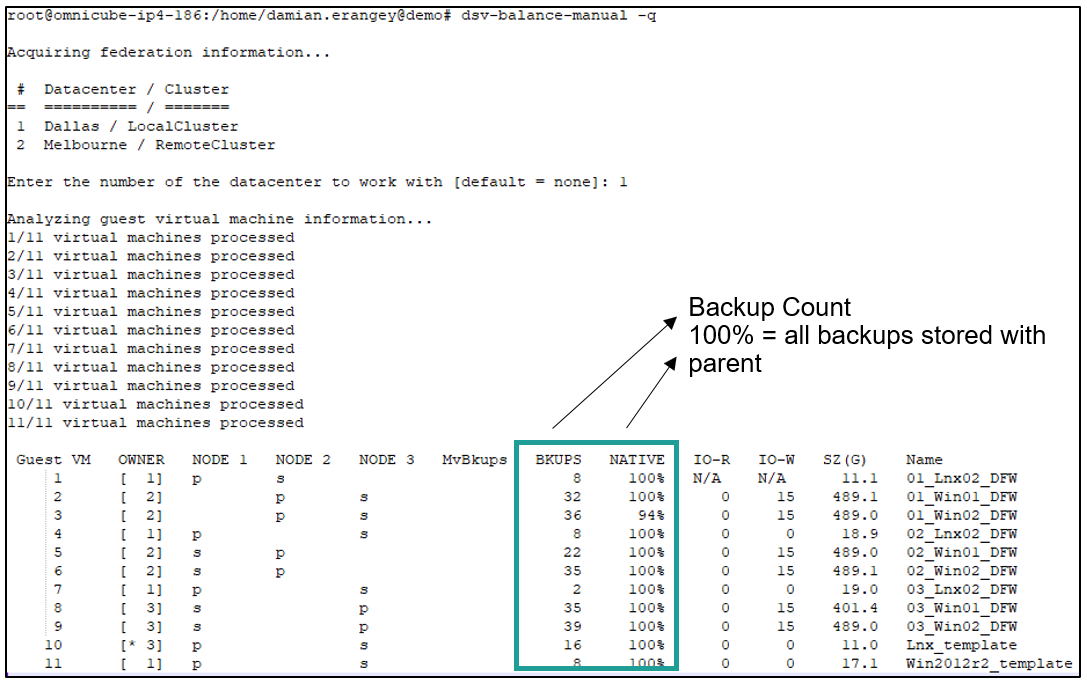
The ds-balance-manual command mainly lists logical information apart from AVAIL (G) this is a physical value. Before migrating a particular data container to another node it may be useful to understand the physical size of the data container (unique VM size) before migration. This is beyond the scope of this topic. HPE technical support can assist with calculation(s) before any such migration may be executed.
Manually migrating data containers and its associated backups to another node
- Issue the command dsv-balance-manual
- Select required Datacenter/Cluster
- vi the generated csv file ‘ dsv-balance-manual –csvfile /tmp/balance/replica_distribution_file_Dallas.csv’
- Press ‘i’ for insert mode
- using the arrow keys, move to the desired column of the virtual machine’s data container you wish to migrate. Note as of 3.7.6 you can either move the primary or secondary data container, for earlier versions you can only move the secondary data container.
- Delete the ‘p’ or ‘s’ from that column and using the arrow keys move to the column of the node you wish to migrate the data container to, insert an ‘s’ or ‘p’ character in the appropriate column.
- Once complete save you changes to the csv file and exit buy pressing ‘ESC’ and ‘:wq!’
- To migrate the data container enter the command ‘dsv-balance-manual –csvfile /tmp/balance/replica_distribution_file_Dallas.csv
The commands re-reads the csv file looking for any changes in the file, if found it will automatically migrate the appropriate container and it associated backups to the desired node.
I have created a short video below outlining this process. In this video I move the primary data container (and associated backups) of the first VM in the generated csv file from node 3 to node 2. If you have any questions in regards to this process I recommend contacting HPE technical support who can walk you through these steps.
In the next post we will explore how to list and calculate local and remote backup sizes.

Leave a comment