
Speaking with a customer recently I was asked how data, that makes up the contents of a virtual machine is stored within a HPE SimpliVity cluster and how does this data affect overall available capacity within that cluster.https://damianerangey.com/hpe-simplivity/
This is essentially a two part question, the first part is relatively straight forward however, answering the second part of the question leads to the time old response “it depends! ” which can only be answered by digging a little deeper with the customer into their specific environment and ensuring they have a good grasp of the HPE Simplivity architecture.
With that in mind, having an understanding of the architecture is beneficial for any existing or perspective HPE SimpliVity customer and with that in mind I have decided to set out a 5 to 6 part series explaining how virtual machine data is stored and managed within a HPE SimpliVity Cluster and how this will lead to an understanding of data consumption within a HPE SimpliVity cluster.
The aim of these posts are to dig a little deeper into HPE SimpliVity architecture and to set straight some of the misconceptions in relation to the underlying architecture. The series will be split into the following topics.
- The data creation process. How Data is stored within a HPE SimpliVity Cluster.
- How the HPE SimpliVity platform automatically manages this data.
- How as administrators we can manage this data.
- Understanding and reporting managing capacity.
The aim is to develop an understanding of the underlying architecture and apply this knowledge gained within the topics to your own environment.
The data creation process – How Data is stored within a HPE SimpliVity Cluster
Data associated with a VM is not spread across all hosts within a cluster, rather data associated with a VM is stored in HA pairs on two nodes within the overall cluster.
Each time a new VM is created (or moved) to a HPE SimpliVity Datastore, two copies of the virtual machine are automatically created within the cluster regardless of the number of nodes within that cluster (except for a single node cluster), the redundancy of all HPE SimpliVity virtual machines are N+1 (excluding backups).
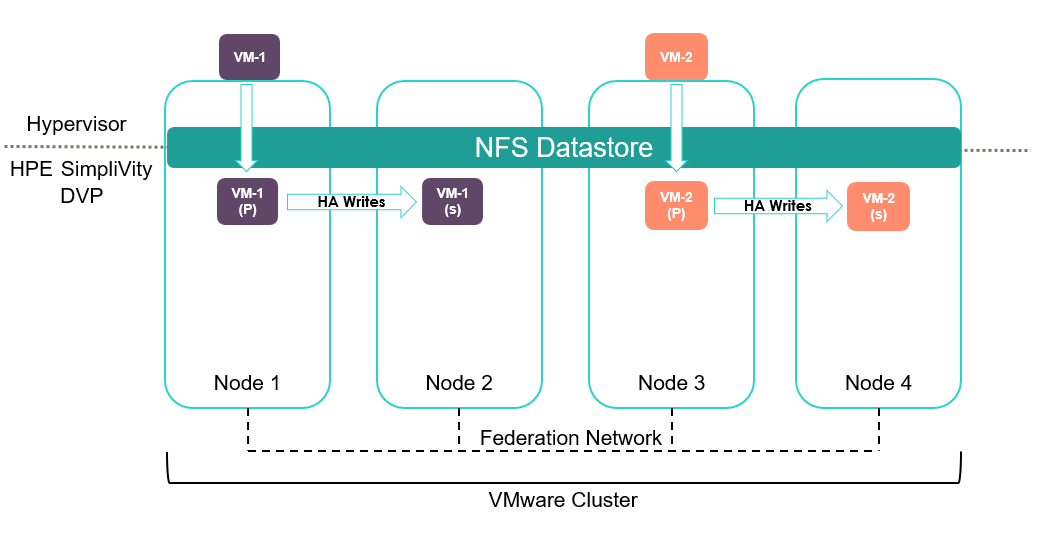
If we look at the diagram above, I have taken an example of a 4 node HPE SimpliVity cluster and from a VMware perspective all nodes are accessing a single shared SimpliVity Datastore (however we can have more than one).
Think of the NFS Datastore as the entry point into the HPE SimpliVity file system, the DVP (Data Virtualisation Platform) presents a simple root level file system whose contents are the directories within the NFS Datastore. The DVP maps each Datastore operation into a HPE SimpliVity Operation. i.e. read / write , make a directory , remove a directory etc.
The Data Container creation process
When a virtual machine is either migrated to a SimpliVity Datastore or created as per any standard mechanism i.e. from a template, cloned etc., a new folder will be created on the NFS Datastore containing all the files associated with that virtual machine.
The HPE SimpliVity DVP will manage this process. A data container is created for this virtual machine, that data container contains the entire contents of that VM. Various services within the DVP are responsible for ownership and activation of this data container along with making it highly available.
The data container is its own file system. The DVP organizes its metadata, directories and files within those directories as a hash tree of SHA-1 hashes. It processes all typical file system operations along with read and write operations.
Unlike traditional file systems that map file offset ranges to a set of disk LBA ranges, the HPE SimpliVity DVP relies on the SHA-1 hash (signature) of any data that it references. Data is divided into 8K objects by the DVP and these objects are managed by the ObjectStore.
Placement of Data Containers – Intelligent Workload Optimizer
The HPE SimpliVity Intelligent Workload Optimizer (or IWO for short) will take a multidimensional approach on which nodes to place the primary and secondary data containers, based on node storage and performance metrics. In our simplified diagram, IWO choose VM-1’s data container to be located on node 1 and 2 and VM-2’s data containers to be located on nodes 3 and 4 respectively.
IWO’s Its aim is to balance workloads across nodes, this is to try to avoid costly migration of a data container in the future.
Primary and Secondary Data Containers
One Data Container will be chosen as the primary (or active) copy of the data (actively serving all I/O) while a secondary copy is kept in HA sync at all times. HA writes occur over the 10Gb Federation network between nodes.
IWO will always enforce data locality, thus pinning (through DRS affinity rules) a virtual machine to the two nodes that contain a copy of the data. This is also handled at initial virtual machine creation.
In the first diagram VM-1 was placed on Node 1 via IWO, thus the data contained on node 1 is the primary (or active) copy of data.
In the below diagram, VM-1 has been migrated to node 2, as a result the secondary (or standby) data container is automatically activated to become the primary and the data container on Node 1 is set to secondary. HA writes are the reversed. Virtual machines are unaware of this whole process.
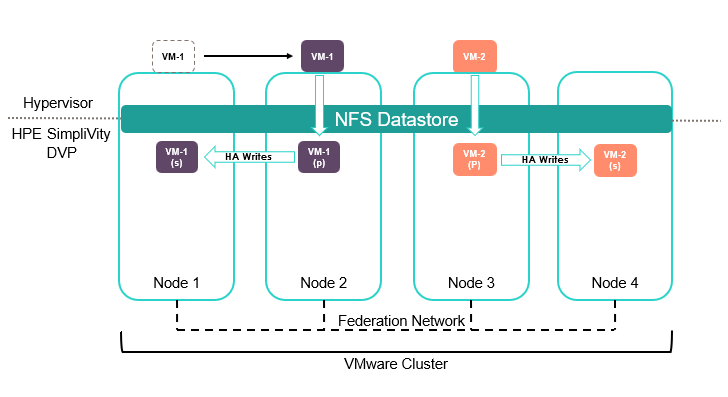
It is possible and supported to run virtual machines on nodes that does do not contain primary or secondary copies of the data. In this scenario I/O travels from the node over the federation network back to where the primary Data Container is located.

Understanding utilized space
Now that we have an understanding of primary and secondary data containers we can see that space utilized to store a virtual machine is already consumed within the cluster from initial creation of a virtual machine (both for its primary and secondary copy). This value may increase or decrease depending on de-duplication and compression during the life of the VM.
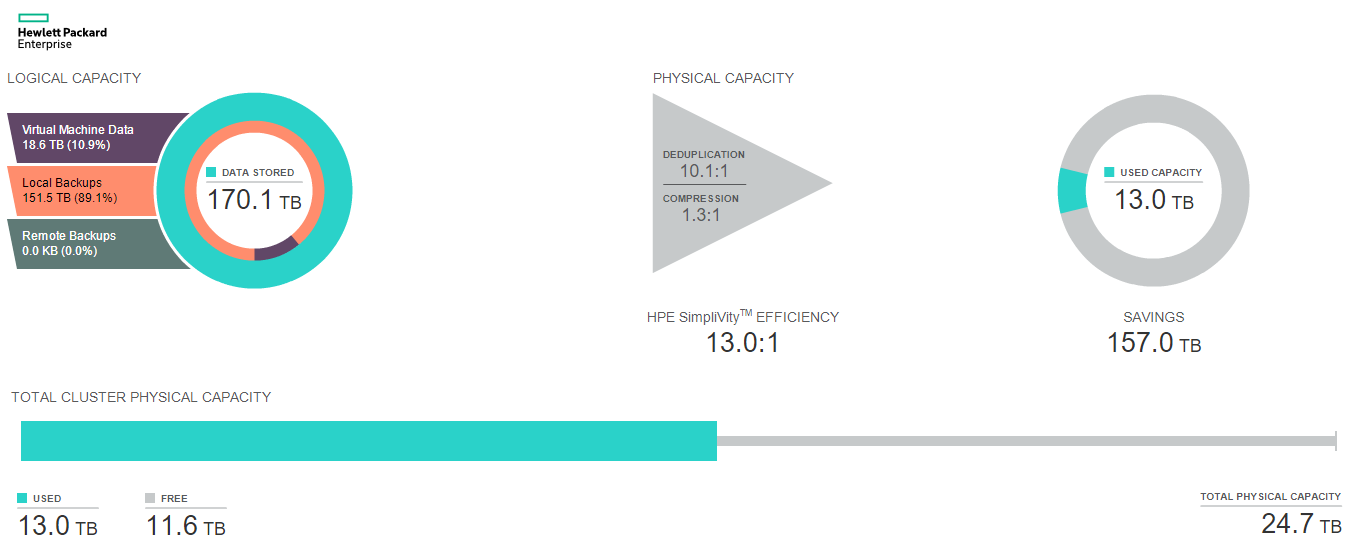
In this post I am ignoring logical capacity and concentrating on physical capacity. In regards to physical capacity, total physical cluster capacity is calculated and displayed as the total aggregate available physical capacity from all nodes within that cluster. We do not report on individual node capacity within the vCenter plugin (however it is possible to get this information from the command line utilizing the command dsv-balance-show).
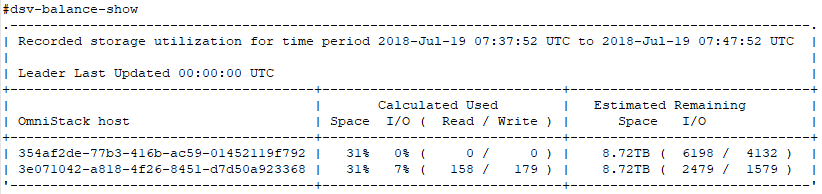
When a new vm is created you can think of the overall used cluster space value dropping by a factor of two each time, as we create a primary and secondary copy of that VM within the cluster.
For example, if a new vm created consumes 10GB of unique on-disk space after de-duplication and compression, total on-disk data stored within the cluster will be 20GB’s. 10GB’s on one node and 10GB’s on a second node.
Failure scenarios
A full explanation of failure scenarios is beyond the scope of this post and is something I am planning to address in a future post, but for now, suffice to say, should a node containing the primary (active) copy of the data fail we automatically activate the secondary copy of the data to become the new primary, again this process is seamless to the virtual machine (as long as the hypervisor did not crash!)
Temporarily losing a node in cluster will not impact on the ability for existing VM’s to stay running from a capacity perspective, regardless of how much capacity you have already used within your HPE SimpliVity cluster as the DVP has already consumed the available space required for the primary and secondary copy of the data, the overall remaining capacity will reduce during that scenario but this would only be for any new VM’s created within the cluster.

Leave a comment